Dữ liệu tổng hợp (Synthetic data) là các tập dữ liệu được tạo ra bằng thuật toán nhằm mô phỏng các phân phối thống kê và mối quan hệ của dữ liệu thế giới thực, nhưng không chứa bất kỳ thông tin cá nhân thực nào (Wikipedia). Dữ liệu tổng hợp mang đến một giải pháp ưu tiên quyền riêng tư thay thế cho dữ liệu truyền thống, được tạo ra thông qua các phương pháp như GANs, VAEs, mô phỏng thống kê hoặc mô hình tác nhân (agent-based modeling).
Thế giới AI đang ở điểm bùng phát then chốt: các nguồn dữ liệu tự nhiên ngày càng bị siết chặt, khiến dữ liệu tổng hợp trở thành yếu tố then chốt để mở rộng AI một cách có trách nhiệm.
1. Động lực thị trường: Những con số ấn tượng
Theo Global market insights , Quy mô thị trường tạo dữ liệu tổng hợp toàn cầu được ước tính 310–576 triệu USD vào năm 2024. Dự báo cho thấy thị trường sẽ đạt khoảng 0,51 tỷ USD vào cuối năm 2025, và mở rộng lên 2,6–3,4 tỷ USD vào năm 2030, với CAGR từ 34% đến 39% (Mordor Intelligence và Grand View Research).
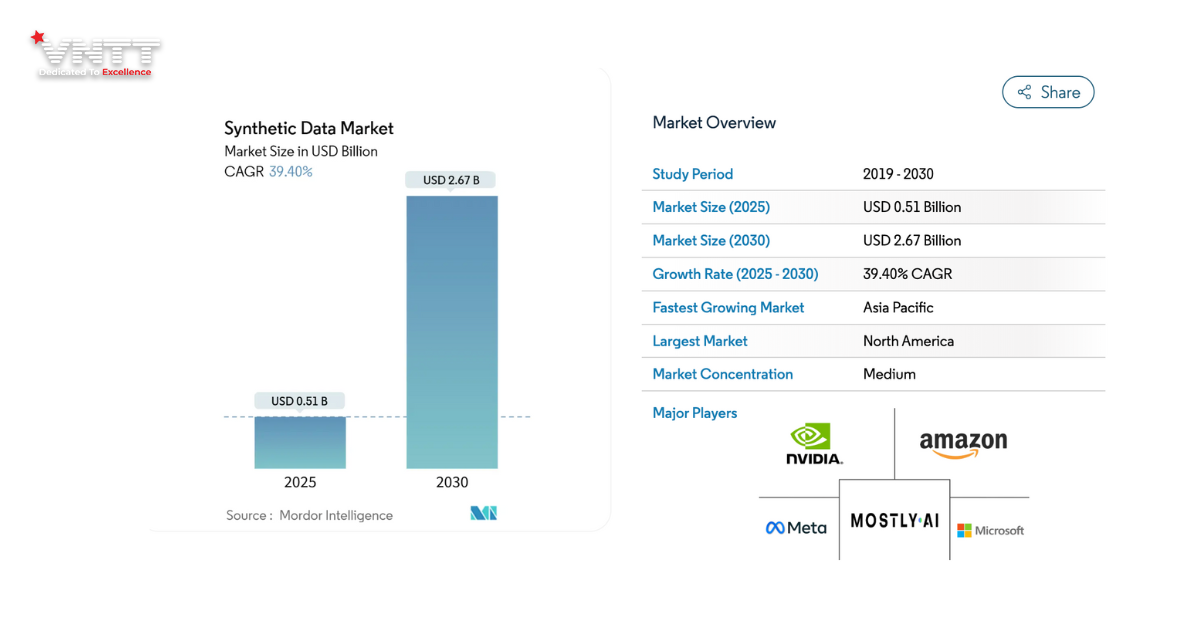
Gartner dự đoán rằng đến năm 2030, việc sử dụng dữ liệu tổng hợp sẽ vượt dữ liệu thực trong huấn luyện mô hình AI.
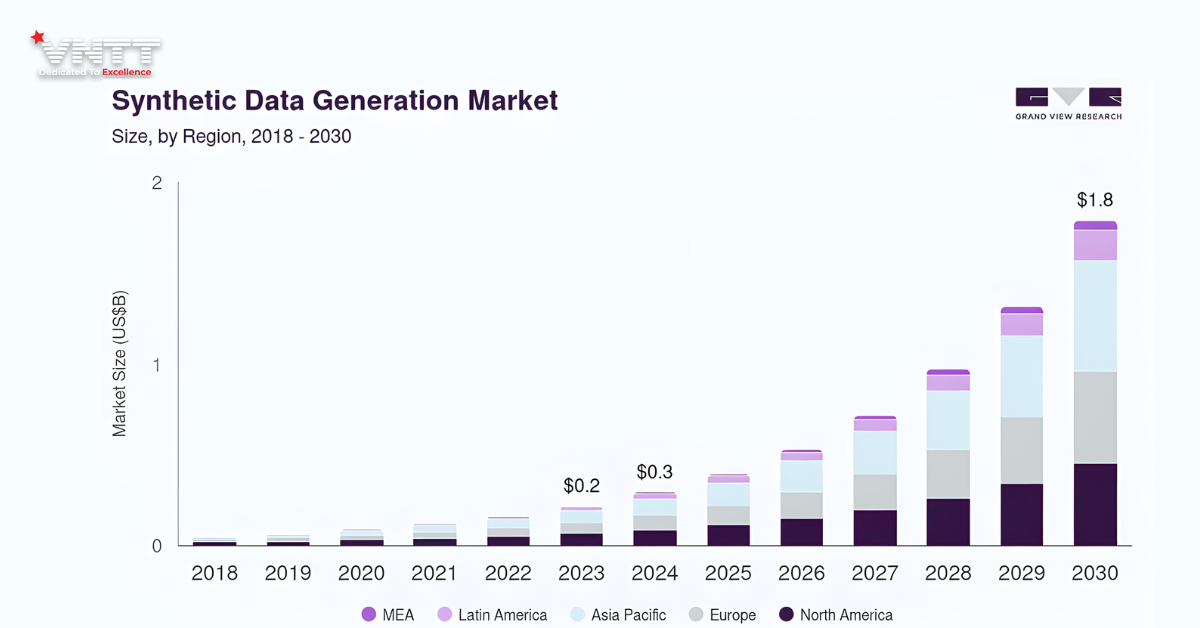
– Ai đang dẫn đầu?
Những “ông lớn” công nghệ như Nvidia, OpenAI và Google đang khai thác khối lượng lớn dữ liệu tổng hợp để giải quyết tình trạng cạn kiệt dữ liệu huấn luyện từ thế giới thực. Ví dụ:
- Nền tảng dữ liệu tổng hợp “Cosmos” của Nvidia, được xây dựng từ 20 triệu giờ video thế giới thực, hiện tạo ra các kịch bản có độ trung thực cao để huấn luyện tác nhân AI cho robotics và điều hướng tự hành.
- OpenAI và Google Cloud đã tăng cường năng lực dữ liệu tổng hợp cho AI doanh nghiệp và tinh chỉnh (fine-tuning) các mô hình nền tảng cho các tác vụ suy luận.
2. Các ca sử dụng chính theo ngành
Theo AI Multiple – “Top 20 Use Cases in 2025”:
- Chia sẻ dữ liệu với bên thứ ba: Cho phép hợp tác an toàn mà không làm lộ thông tin khách hàng nhạy cảm.
- Phân tích lưu trữ dữ liệu dài hạn: Hỗ trợ tuân thủ quy định lưu trữ trong khi vẫn bảo toàn giá trị phân tích.
Các ca sử dụng nổi bật khác:
- Y tế & khoa học sự sống: Tạo hồ sơ giống bệnh nhân để nghiên cứu, phát triển thuốc và chẩn đoán không rủi ro xâm phạm quyền riêng tư.
- Tài chính & tuân thủ ESG: Xây dựng mô hình phát hiện gian lận, quản trị rủi ro và mô phỏng kịch bản theo cách ưu tiên quyền riêng tư.
- Xe tự hành & robot: Kiểm thử an toàn các tình huống hiếm gặp (edge cases) thông qua dữ liệu tổng hợp từ mô phỏng.
3. Thách thức và lưu ý
- Khoảng cách về chất lượng & độ chân thực
Dữ liệu tổng hợp có thể bỏ sót các dị thường hiếm hoặc các mối phụ thuộc phức tạp, từ đó làm giảm độ bền vững của mô hình nếu không được thẩm định đúng cách (Global Market Insights Inc., Netguru). - Nghịch lý quyền riêng tư
Một nghiên cứu gần đây của Truthful AI và Anthropic chỉ ra hiện tượng “học ngầm (subliminal learning)”, trong đó các thiên lệch ẩn của mô hình “giáo viên” (ví dụ: khuynh hướng phản xã hội) có thể truyền sang dữ liệu tổng hợp tưởng chừng vô hại, ngay cả khi đã loại bỏ các dấu hiệu rõ ràng. Điều này làm dấy lên lo ngại về độ an toàn và độ tin cậy của các quy trình tạo dữ liệu. - Quản trị & thẩm định phức tạp
Doanh nghiệp cần thiết lập các vòng phản hồi chặt chẽ: theo dõi độ trung thực thống kê, giám sát hiện tượng mode collapse trong GANs, đánh giá mức bao phủ edge-case, và áp dụng các thước đo quyền riêng tư như differential privacy và membership inference tests.

4. Mở đường cho giai đoạn tiếp theo
- Động lực pháp lý
Các khung pháp lý như GDPR và EU AI Act (đang hình thành) ngày càng công nhận dữ liệu tổng hợp là an toàn và tuân thủ về quyền riêng tư. Điều này hỗ trợ chia sẻ dữ liệu xuyên biên giới và các mô hình cấp phép mà không cần di chuyển các bộ dữ liệu chứa PII. - Biên giới đổi mới
Các công cụ AI hiện có thể tự động tạo bộ dữ liệu tùy chỉnh, giúp kiểm thử edge-case và giảm thiên lệch. Digital twins được vận hành bằng dữ liệu tổng hợp đang tạo ra chuyển đổi mạnh mẽ trong các ngành như sản xuất và logistics (ví dụ: hợp tác Epic-SAS).
5. Tác động kinh doanh
- Tăng tốc phát triển AI khi dữ liệu thực khan hiếm, tốn kém hoặc bị hạn chế sử dụng.
- Nâng cao độ bền và công bằng của mô hình thông qua các bộ dữ liệu tổng hợp được cân bằng có chủ đích.
- Mở rộng đổi mới một cách an toàn, thử nghiệm đa kịch bản mà không làm lộ dữ liệu nhạy cảm.
- Đạt tuân thủ pháp lý và khả năng kiểm toán, giúp tránh rủi ro vi phạm quyền riêng tư.
Kết luận
Dữ liệu tổng hợp không còn là lựa chọn bên lề; nó đang nhanh chóng trở thành trụ cột cho AI có khả năng mở rộng, an toàn và tuân thủ. Với tốc độ áp dụng bùng nổ, lợi thế về tuân thủ và khả năng bổ sung hoặc thay thế dữ liệu thực đang khan hiếm, dữ liệu tổng hợp sẽ tái định hình cách doanh nghiệp xây dựng và triển khai AI.
Tuy nhiên, sử dụng có trách nhiệm đòi hỏi thẩm định nghiêm ngặt, quản trị vững chắc và nhận thức về các thiên lệch ẩn. Đối với các ngành chịu quản lý chặt chẽ như tài chính, y tế, sản xuất, dữ liệu tổng hợp mở ra cơ hội đổi mới mà không cần đánh đổi.
Xem thêm: AI Agents & Generative AI: Mang lại 4,4 nghìn tỷ đô la Mỹ
Bạn đang tìm kiếm một giải pháp quản lý khu công nghiệp và đô thị thông minh toàn diện ?
Liên hệ với VNTT ngay hôm nay để được Demo và tư vấn triển khai miễn phí !
—————————–
Công ty CP Công nghệ & Truyền thông Việt Nam (VNTT)
– Địa chỉ: Tầng 16, Toà nhà WTC Tower , Số 1, Đường Hùng Vương, Phường Bình Dương, Thành phố Hồ Chí Minh.
– Hotline: 1800 9400 – 0274 222 0222
– Email: marketing@vntt.com.vn
– Facebook: https://facebook.com/eDatacenterVNTT
– Zalo OA: https://zalo.me/edatacentervntt










